VPA関数を使った資源量推定
市野川桃子 & 宮川光代
2026-07-14
vpa.RmdVPAの実施
データの読み込み
library(frasyr)
caa <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex2_caa.csv", row.names=1)
waa <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex2_waa.csv", row.names=1)
maa <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex2_maa.csv", row.names=1)
dat <- data.handler(caa=caa, waa=waa, maa=maa, M=0.5)
# VPAによる資源量推定
res_vpa <- vpa(dat,fc.year=2015:2017,tf.year = 2015:2016,
term.F="max",stat.tf="mean",Pope=TRUE,tune=FALSE,p.init=0.5)
res_vpa$Fc.at.age # 将来予測やMSY計算で使うcurrent F (fc.yearのオプションでいつのFの平均かが指定される)
#> 0 1 2 3
#> 0.4901521 1.1503151 1.3131002 1.3131001
plot(res_vpa$Fc.at.age,type="b",xlab="Age",ylab="F",ylim=c(0,max(res_vpa$Fc.at.age)))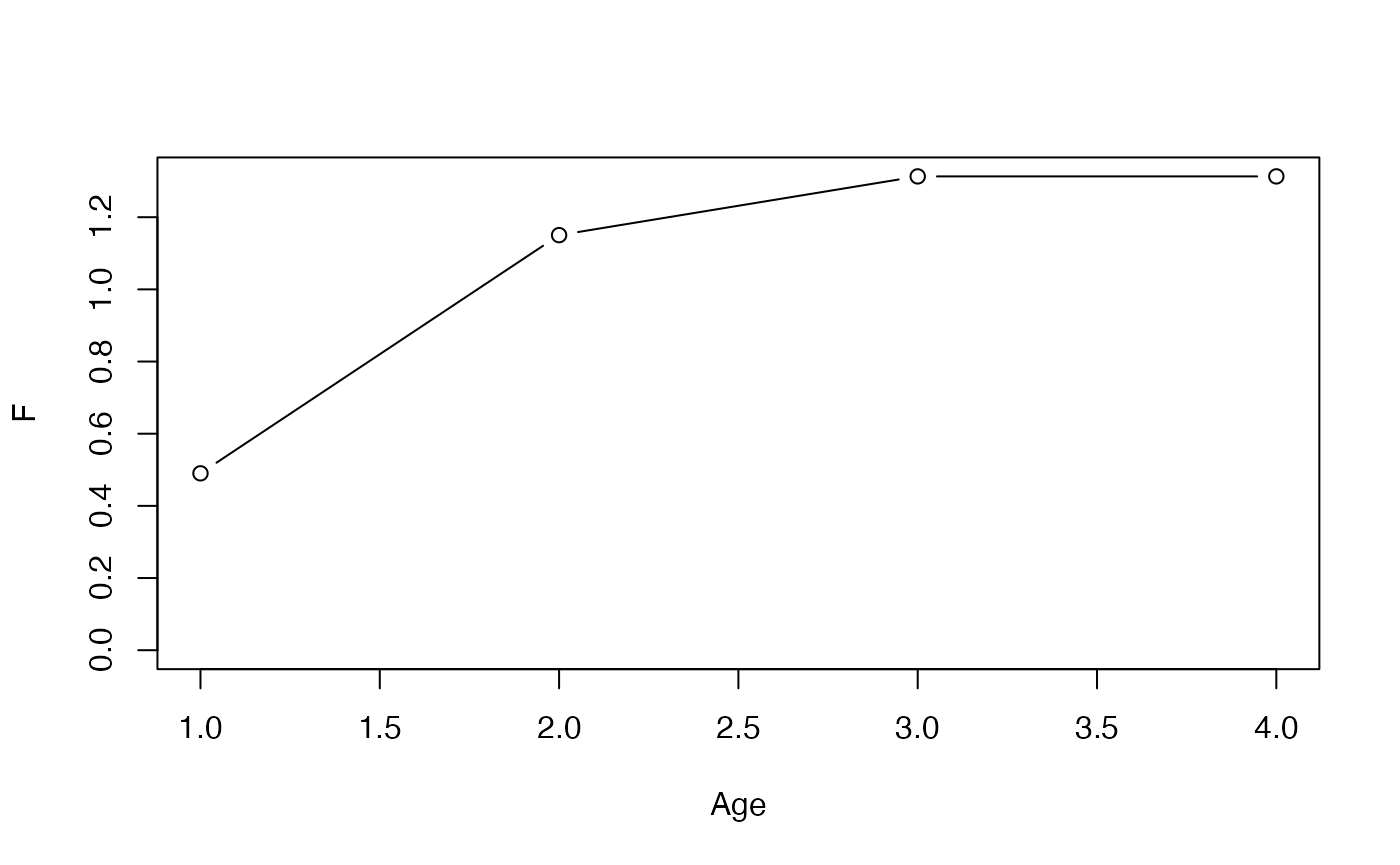
VPA結果を外部から読み込む場合
- read.vpa数を使って読み込めます
- out.vpa関数による出力と同じ書式になりますので、out.vpa関数でひな形ファイルを作成してから、エクセルでそれを編集し、read.vpa関数で読むと良いと思います
#out.vpa(res_vpa) # vpa.csvというファイルが作成されます。VPAの結果のグラフ出力となるvpa.pdfも出力されます。
res_vpa2 <- read.vpa("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex2_vpa.csv") # vpa.csvを編集後、read.vpa関数で読み込みます
#> Pope is TRUE... OK? (mean difference= 0 )
#> Plus group is TRUE... OK?さまざまなVPAのデモ
データの読み込みと整形
# 読み込み
caa <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex1_caa.csv", row.names=1)
waa <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex1_waa.csv", row.names=1)
maa <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex1_maa.csv", row.names=1)
M <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex1_M.csv", row.names=1)
index <- read.csv("https://raw.githubusercontent.com/ichimomo/frasyr/dev/data-raw/ex1_index.csv", row.names=1)
# 整形
dat <- data.handler(caa=caa, waa=waa, maa=maa, index=index, M=0.4)チューニングなしVPAのバリエーション
# p.initは初期値。収束しない場合(Fがゼロになる場合など)は、初期値を変えてみる
# fc.yearは、Fcurrentを計算する範囲。管理基準値と将来予測で使われる。
vout1 <- vpa(dat,tf.year=1997:1999,Pope=TRUE,fc.year=1998:2000,alpha=1,p.init=0.5)
vout1a <- vpa(dat,tf.year=1997:1999,Pope=FALSE,fc.year=1998:2000,alpha=1,p.init=0.5)
vout1b <- vpa(dat,tf.year=1997:1999,Pope=TRUE,fc.year=1998:2000,alpha=0.5,p.init=0.5)
#> [1] "Warning! The estimated F for the older ages may not be accurate if C<<N is not satisfied for the older ages."
vout1c <- vpa(dat,tf.year=1999:1999,Pope=TRUE,fc.year=1998:2000,alpha=1,p.init=0.5)
plot_vpa(vout1c, plot_year=1991:2000) # 様々な結果のプロット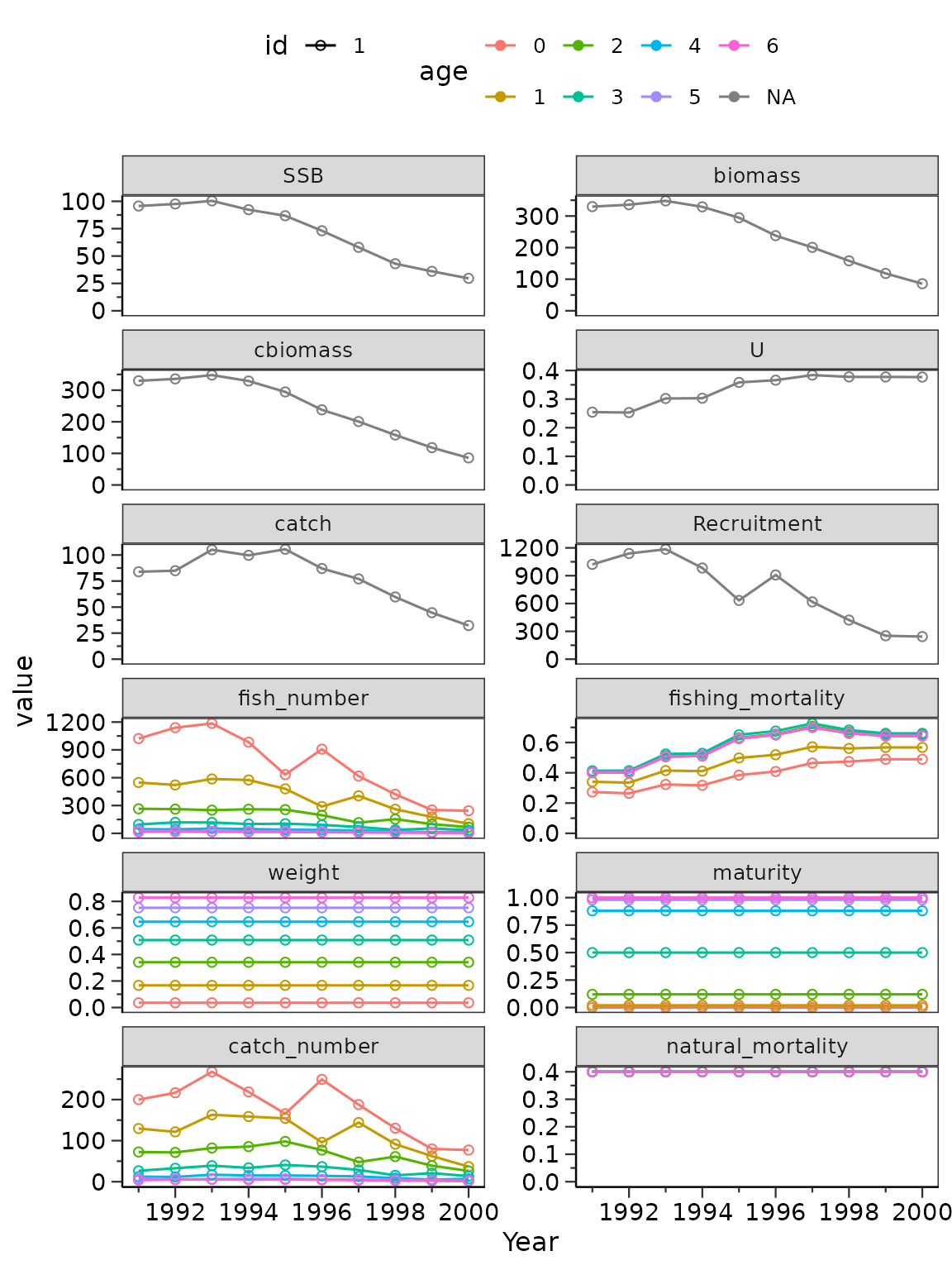 ## チューニングVPAのバリエーション
## チューニングVPAのバリエーション
## vout2; チューニング,選択率updateなし
vout2 <- vpa(dat,tune=TRUE,sel.update=FALSE,Pope=FALSE,
tf.year=NULL,sel.f=vout1$saa$"2000", # 選択率の仮定
abund=c("N"),min.age=c(0),max.age=c(6), # 資源量指数の設定
alpha=1,p.init=0.5,max.dd = 0.00001,fc.year=1998:2000)
## vout3; チューニング,選択率update
# tf.yearは選択率の初期値として用いられる。
vout3 <- vpa(dat,tune=TRUE,sel.update=TRUE,Pope=FALSE,
tf.year=1997:1999,sel.f=NULL,
abund=c("N"),min.age=c(0),max.age=c(7), # 資源量指数の設定
alpha=1,p.init=0.5,max.dd = 0.00001,fc.year=1998:2000)
## チューニング,選択率全推定
# tf.yearも sel.fも必要ない
vout4 <- vpa(dat,tune=TRUE,sel.update=FALSE,term.F="all",
tf.year=NULL,sel.f=NULL,
abund=c("N"),min.age=c(0),max.age=c(6), # 資源量指数の設定
alpha=1,p.init=0.5,max.dd = 0.00001,fc.year=1998:2000)RidgeVPA
## チューニング,選択率update, ridgeVPA
# lambda, penalty, betaの三つの引数を追加する
vout5 <- vpa(dat,tune=TRUE,sel.update=TRUE,Pope=FALSE,
tf.year=1997:1999,sel.f=NULL,
abund=c("N"),min.age=c(0),max.age=c(7), # 資源量指数の設定
alpha=1,p.init=0.5,max.dd = 0.00001,fc.year=1998:2000,
lambda=0.01, # ridge penaltyの大きさ(下記のlambdaの決め方を参考にして探索した値を代入)
penalty="p", # penalty項の与え方("p" or "f" or "s")
beta=2) # penaltyの種類:1=lasso回帰, 2=ridge回帰RidgeVPAにおけるlambdaの決め方
# autocalc_ridgevpaという関数を使用(初めに0-1の間で0.1刻みで探索し,モーンズρが最も低かったlambdaのところで,次はその値の前後±0.1の範囲を0.01刻みで探索する仕様になっています).
#※VPAの計算を何度も繰り返し行うので,TMB=TRUEでない場合はかなりの計算時間がかかります
ridge_res <- autocalc_ridgevpa(
input=vout3$input,
target_retro="F", # レトロスペクティブバイアスを何について計るか;"F", "B", "SSB", "N", "R"の中から選択する
n_retro=5, # レトロスペクティブ解析で遡る年数
b_fix=TRUE) # レトロスペクティブ解析内でbを固定するか
ridge_res$min_penalty # target_retroで指定した指標のモーンズρが最小になるようなlambdaの値.これをlambdaとして代入するRidgeVPAの特殊な設定(etaをいれる場合)
# ペナルティー項の重みを年齢によって変える場合はeta, eta.ageを追加する
vout6 <- vpa(dat,tune=TRUE,sel.update=FALSE,term.F="all",
tf.year=NULL,sel.f=NULL,
abund=c("N"),min.age=c(0),max.age=c(6),
alpha=1,p.init=0.5,max.dd = 0.00001,fc.year=1998:2000,
lambda=0.01,
penalty="p",
beta=2,
eta=0.99, # penaltyを年齢で分けて与えるときにeta.ageで指定した年齢への相対的なpenalty(0~1).autocalc_ridgevpaで探索可能
eta.age=0) #penaltyを年齢で分けるときにetaを与える年齢(0=0歳(加入), 0:1=0~1歳)
# autocalc_ridgevpaを用いてlambdaとetaの2次元探索を行う(ここでは2段階探索は行っていません)
#※lambdaとetaをグリッド探索するのでかなりの計算時間がかかります
ridge_res2 <- autocalc_ridgevpa(
input=vout6$input,
target_retro="F",
n_retro=5,
b_fix=TRUE,
bin=0.1) # lambdaとetaの探索刻み幅を指定
ridge_res2$min_penalty # target_retroで指定した指標のモーンズρが最小になるようなlambdaとetaの組み合わせ